HTCRAWL
Htcrawl is nodejs module for the recursive crawling of single page applications (SPA) using javascript.
It uses headless chrome to load and analyze web applications and it's build on top of Puppetteer
from wich it inherits all the functionalities.
With htcrawl you can roll your own DOM-XSS scanner with less than 60 lines of javascript!! (see below)
Some examples of what (else) you can do with htcrawl:
- Advanced scraping of single page applications (SPA)
- Intercept and log all requests made by a webpage
- Build tools to detect security vulnerabilities
- Automate testing of UI, javascript ecc
You may also try htcap, a vulnerability scanner built on top of htcrawl.
Basic usage
Very basic example for code to print all ajax requests.
const htcrawl = require('htcrawl');
// Get instance of Crawler class
const crawler = await htcrawl.launch("https://htcrawl.org");
// Print out the url of ajax calls
crawler.on("xhr", e => {
console.log("XHR to " + e.params.request.url);
});
// Start crawling!
crawler.start();
Demo Video
Short video of the crawl engine in action.
API Reference
The API manual can be found here
Download
$ npm -i htcrawl $ # or $ git clone https://github.com/fcavallarin/htcrawl.git && cd htcrawl && npm i && cd ..
or visit the github page here
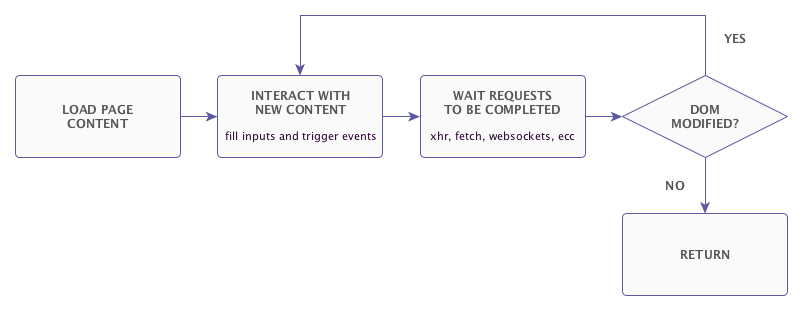
Crawl flow
The diagram below shows the recursive crawling process.
Examples
1. DOM XSS Scanner
Simple DOM XSS scanner
const targetUrl="https://htcap.org/scanme/domxss.php";
const options = {headlessChrome:1};
var pmap = {};
const payloads = [
";window.___xssSink({0});",
"<img src='a' onerror=window.___xssSink({0})>"
];
function getNewPayload(payload, element){
const k = "" + Math.floor(Math.random()*4000000000);
const p = payload.replace("{0}", k);
pmap[k] = {payload:payload, element:element};
return p;
}
async function crawlAndFuzz(payload){
var hashSet = false;
// instantiate htcrawl
const crawler = await htcrawl.launch(targetUrl, options);
// set a sink on page scope
crawler.page().exposeFunction("___xssSink", key => {
const msg = `DOM XSS found:\n payload: ${pmap[key].payload}\n element: ${pmap[key].element}`
console.log(msg);
});
// fill all inputs with a payload
crawler.on("fillinput", async function(e, crawler){
const p = getNewPayload(payload, e.params.element);
try{
await crawler.page().$eval(e.params.element, (i, p) => i.value = p, p);
}catch(e){}
// return false to prevent element to be automatically filled with a random value
return false;
});
// change page hash before the triggering of the first event
crawler.on("triggerevent", async function(e, crawler){
if(!hashSet){
const p = getNewPayload(payload, "hash");
await crawler.page().evaluate(p => document.location.hash = p, p);
hashSet = true;
}
});
try{
await crawler.start();
} catch(e){
console.log(`Error ${e}`);
}
crawler.browser().close();
}
(async () => {
for(let payload of payloads){
/* Remove 'await' for parallel scan of all payloads */
await crawlAndFuzz(payload);
}
})();
2. Advanced content scraper
Crawls a single page application looking for emails.
const targetUrl="https://htcap.org/scanme/ng/";
const options = {headlessChrome:1};
function printEmails(string){
const emails = string.match(/([a-z0-9._-]+@[a-z0-9._-]+\.[a-z]+)/gi);
if(!emails) return;
for(let e of emails)
console.log(e);
}
htcrawl.launch(targetUrl, options).then(async crawler => {
crawler.on("domcontentloaded", async function(e, crawler){
const selector = "body";
const html = await crawler.page().$eval(selector, body => body.innerText);
printEmails(html);
});
crawler.on("newdom", async function(e, crawler){
const selector = e.params.rootNode;
const html = await crawler.page().$eval(selector, node => node.innerText);
printEmails(html);
});
crawler.start().then(crawler => {
crawler.browser().close();
}).catch(err => {
console.log(`Error: ${err}`);
});
});
About
Htcrawl has been written by Filippo Cavallarin.
Please report bugs, comments ecc to filippo.cavallarin[]wearesegment.com
This project is son of Htcap (https://github.com/fcavallarin/htcap | https://htcap.org)
Licensing
This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or(at your option) any later version.